Documentation des ensembles de données
Date de mise à jour : 2024-08-01
Fournisseurs des ensembles de Données
Les ensembles de Données en graphique
L’ensemble des archives est représenté par les graphiques ci-dessous.
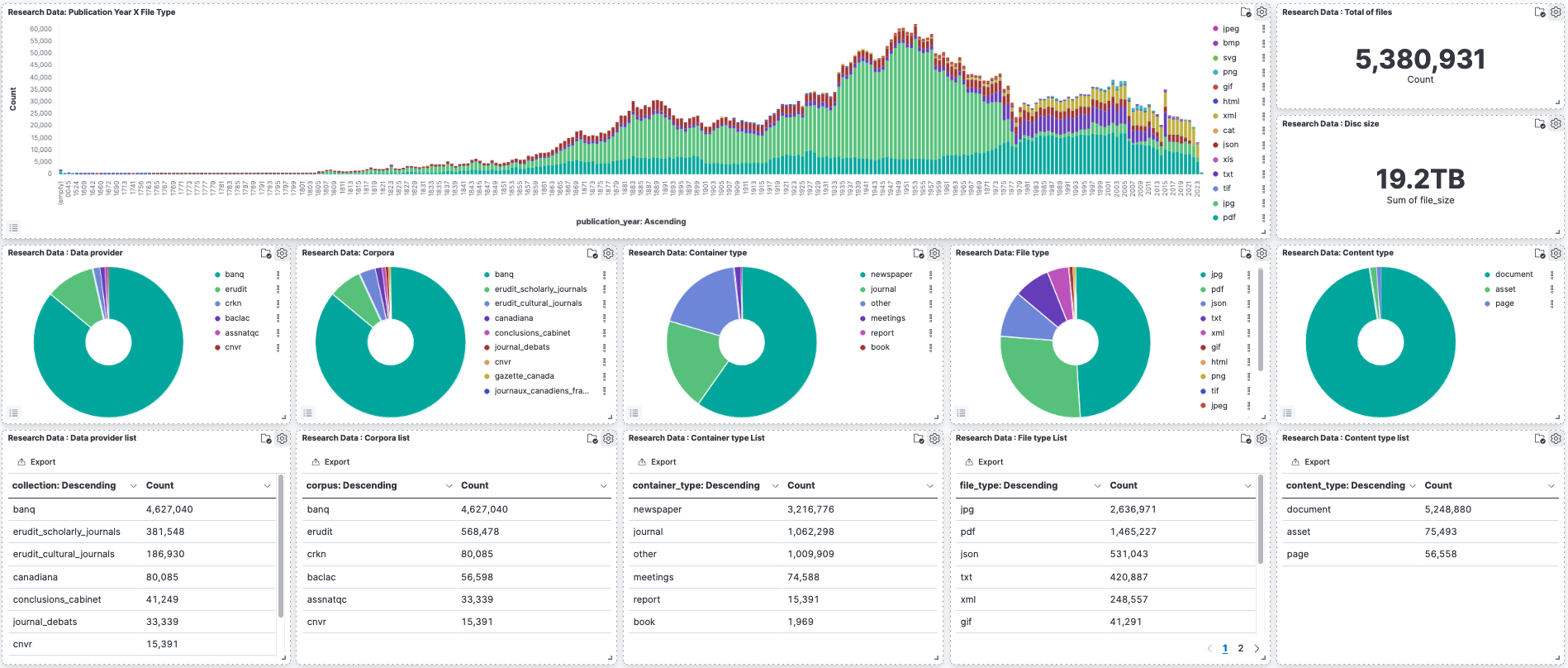
Les données brutes utilisées pour produire ces graphiques sont disponibles dans le fichier ZIP suivant corpus_report_2023_03_03.zip.
Rapport sur les corpus
Le rapport sur les corpus en format TSV (corpus_report_2023_03_30.zip) contient une liste de tous les documents disponibles dans les ensembles de « Données de recherche ». Les champs de ce fichier TSV sont expliqués ci-dessous.
Note
Notez que ce fichier TSV contient trop de lignes pour être ouvert avec Microsoft Excel ou avec Libre Office Calc. Ses données doivent être interrogées à l’aide d’un langage de programmation tel que Python ou autre.
Avec ce fichier TSV, les chercheurs peuvent identifier les fichiers avec lesquels ils veulent travailler en filtrant sur certaines métadonnées de base et estimer la taille du stockage local nécessaire pour stocker les ensembles de données voulus.
Les champs disponibles pour chaque fournisseur de données sont décrits dans le tableau ci-dessous.
Nom du champ |
Champ obligatoire |
BAnQ |
BAC |
RCDR |
Érudit |
|---|---|---|---|---|---|
file_identifier |
oui |
oui |
oui |
oui |
oui |
container_identifier |
no |
no |
no |
no |
oui |
container_title |
no |
oui |
no |
no |
oui |
container_type |
no |
oui |
oui |
oui |
oui |
content_type |
no |
oui |
oui |
oui |
oui |
corpus |
oui |
oui |
oui |
oui |
oui |
collection |
oui |
oui |
oui |
oui |
oui |
file_type |
oui |
oui |
oui |
oui |
oui |
file_size |
oui |
oui |
oui |
oui |
oui |
publication_year |
oui |
oui |
oui |
oui |
oui |
Documentation sur les champs
file_identifier
L’identifiant unique du fichier. Il représente le chemin d’accès au fichier dans le système de fichiers.
container_identifier
L’identifiant unique du conteneur d’un document.
Ce champ n’est pas disponible pour tous les ensembles de données. Certains fournisseurs de données ne fournissent pas cette information.
Il s’agit d’un champ optionnel.
container_title
Le titre du conteneur.
Ce champ n’est pas disponible pour tous les ensembles de données. Certains fournisseurs de données ne fournissent pas cette information.
Il s’agit d’un champ optionnel.
exemple :
Le titre du conteneur peut être le titre d’une revue, d’un journal ou d’un livre.
container_type
Le type du conteneur.
Nous faisons de notre mieux pour mieux identifier cette information pour tous les ensembles de données, même si elle ne nous a pas été fournie.
Il s’agit d’un champ optionnel.
exemple :
revue
journal
réunions
livre
autre
etc.
content_type
Le type du conteneur.
Nous faisons de notre mieux pour mieux identifier ces informations pour tous les ensembles de données, même si elles ne nous sont pas fournies.
Il s’agit d’un champ optionnel.
exemple :
document : le texte intégral se trouve dans le fichier
fichier connexe : représente les fichiers connexes d’un document (images, tableaux, vidéos, fichiers audio, etc.)
page : pas le texte intégral, mais une page d’un document. Généralement disponible dans les ensembles d’images numérisées. Pour avoir accès au texte intégral, il est nécessaire d’identifier le groupe d’images qui appartient à un document. Comme par exemple, le contenu de Conclusions du Cabinet, 1944 à 1979. Malheureusement, parfois il n’y a pas moyen d’agréger les pages d’un document car il n’y a pas de données disponibles pour le conteneur (container_identifer, container_title).
corpus
L’identifiant du fournisseur de Données.
Il s’agit d’un champ obligatoire.
exemple :
banq
baclac
canadiana
erudit
collection
L’identifiant d’une collection fournie par le fournisseur de Données
Il s’agit d’un champ obligatoire.
Dans certains cas, comme par exemple dans l’ensemble de Données Bibliothèque et Archives nationales du Québec, nous ne sommes pas en mesure d’identifier clairement la collection à laquelle appartiennent les fichiers. Dans ce cas, le champ collection est rempli avec l’identifiant du fournisseur de Données.
canadiana_serial (canadiana)
conclusions_cabinet (baclac)
gazette_canada (baclac)
journaux_canadiens_francais (baclac)
erudit_journals (erudit)
banq (banq)
file_type
L’extension de chaque fichier.
Il s’agit d’un champ obligatoire.
exemple :
pdf
xml
gif
jpg
tif
txt
png
file_size
La taille d’un fichier en octets.
Ce champ peut être utilisé pour estimer la taille de l’ensemble de données que le chercheur souhaite télécharger.
Il s’agit d’un champ obligatoire.
publication_year
L’année de publication du contenu disponible dans le fichier.
Nous faisons de notre mieux pour mieux identifier cette information pour tous les ensembles de données, même si elle ne nous a pas été fournie.
Il s’agit d’un champ obligatoire.