Scholarly and Cultural Journals Collection
As of march 2024, the Érudit platform’s collection contains articles from 299 scholarly journals and 43 cultural journals in the humanities, social sciences, arts, and letters from Québec and Canada.
General Information
Added to the Research Data: January 2017
Last update: March 2024
Update periodicity: Yearly, in March
Available formats: PDF, EruditArticle XML, JPG, PNG
Documents’ assets available? Yes (images, video and audio files) Documents’ assets available? Yes (images, video and audio files)
Documents’ metadata available? Yes (EruditArticle XML format)
Data size: 202Gb
Number of files: 568,478
Copyright: The data and all related documentation are subject to copyright. Please consult the data provider website for more details.
Data Subject Area: Social Sciences and Humanities
Note
The official documentation of EruditArticle XML Schema is available at: Érudit Official Documentation.
The EruditArticle Schema is available at: http://www.erudit.org/xsd/article/3.1.0/eruditarticle.xsd
The Data in Graphs
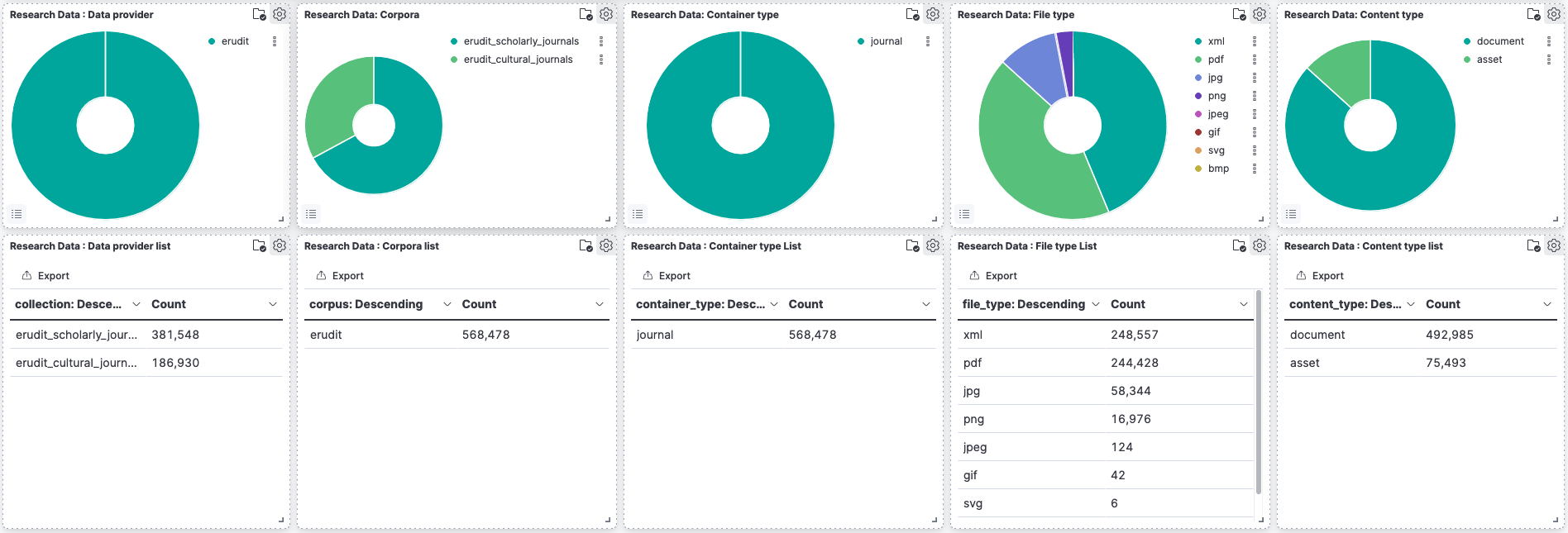
Available formats in “Érudit - Scholarly and Cultural Journals Collection”

Data Overview
The “Erudit - Scholarly and Cultural Journals Collection” dataset contains articles that are grouped by issue and then by journal.
The following sections describe the data structure of the “Erudit - Scholarly and Cultural Journals Collection” dataset and what you will find at the journal, issue and article levels. You will also find some explanations on the EruditArticle XML Schema as well as other useful information that will help you better understand the data.
The Data Structure
The “Erudit - Scholarly and Cultural Journals Collection” dataset has a depth of four levels (counting the assets directory)
erudit
├── journal directory
│ ├── LOGO
│ ├── PUBLICATIONS.xml
│ ├── THEMES.xml
│ └── issue directory
| ├── COVERPAGE_HD *
| ├── COVERPAGE *
| ├── SUMMARY.xml
| └── article directory
| ├── ERUDITXSD300.xml
| ├── PDF.pdf *
| ├── INFOIMG.xml *
| └── assets directory *
| └── asset files *
Journal directory
On the first level, you will find one directory per journal. This directory is named according to a journal’s unique identifier to Erudit (correspond to the revue@id value). In this directory, you will find:
PUBLICATIONS.xml: this XML file (no schema available) contains the list of every issue published for the journal as well as some issue level metadata. Issues published under another name also appear in this list (e.g. if the journal has changed its name)
THEMES.xml: This XML file (no schema available) contains a list of thematic issues of the journal
Issue directories
On the second level, you will find one directory for each issue of a journal. Each directory is named according to an issue’s unique identifier to Erudit (correspond to the numero@id value). In this directory, you will find:
COVERPAGE_HD: If available, the cover page file (High quality)
COVERPAGE: If available, the cover page file (Low quality)
SUMMARY.xml: This XML file (no schema available) contains the metadata used to build the table of contents of the issue. Much of the metadata comes from the ERUDITARTICLE300.xml files (XML file of the articles)
Articles directories
On the third level, you will find one directory for every article of an issue. Each directory is named according to an article’s unique identifier to Erudit (correspond to the article@idproprio value). In this Directory you will find:
ERUDITARTICLE300.xml: This file corresponds to the article in EruditArticle XML format
PDF.pdf: If available, you will also find the associated PDF of the article
INFOIMG.xml: If available, you will find an XML file (no schema available) containing a list of the assets linked to the article
Assets directory
On the fourth level, if available, you will find one directory containing every assets of an article (mainly figures and tables).
PDF availability
The vast majority of the articles on Érudit have an associate PDF file, but some articles using the “complet” (full) workflow do not have one. However, every article using the “minimal” workflow should have an associate PDF file.
Metadata availability
All Érudit documents have an associated EruditArticle XML file.
Minimal vs Complete
The Érudit production workflow is responsible to digitize documents provided by journals. This digitization process consists in converting DOCX, InDesign, JATS, PDF and other files to XML (following the EruditArticle Schema).
Depending on the nature of the journals and some other technical aspects, the articles on Érudit are produced using one of these two types of processing:
“minimal” : metadata + references only (no full-text)
“complet” (full) : minimal + structured body (full-text)
The main difference between these two types of processing concerns the treatment of the body of the article where, on the one hand, the full (“complet”) version has the full-text fully tagged and, on the other hand, the “minimal” version has only the metadata of the document and its references.
The way to distinguish between one and another is inspecting the attribute article@qualtraitement.
Processing Type |
File |
Attribute value |
XML Path |
|---|---|---|---|
minimal |
ERUDITXSD300.xml |
minimal |
article@qualtraitement=”minimal” |
complet |
ERUDITXSD300.xml |
complet |
article@qualtraitement=”complet” |
Availability of the Text of the Articles
Whether with the “minimal” workflow or with the full (“complet”) workflow, the text of the article is always available. However, its quality may vary.
“Complet” workflow: The body of the article is structured in XML. Every parts of the body are identified semantically (section, paragraph, list, footnotes, etc.).
-
“Minimal” workflow: For the current minimal workflow (new issues), the text of the article is extracted from the source file sent by the journal (mainly DOCX or InDesign files). The raw text of the article is kept for indexing and tagged inside a “texte” element. This element contains the @typetexte=”libre” attribute. The value “libre”, means the text is unstructured (raw).
archive projects: All archive projects follow the “minimal” workflow. The majority of these projects are made from OCRised PDF and so, the quality of the raw text kept for indexing is lower. OCRised content may be identify with the @typetexte”roc” attribute. The value “roc” is the abbreviation for ocr in French.
Workflow |
Attribute / value |
XML Path |
|---|---|---|
current |
typetexte=”libre” |
article.corps@typetexte=”libre” |
archive |
typetexte=”roc” |
article.corps@typetexte=”roc” |
Article types
The articles in the “Erudit - Scholarly and Cultural Journals Collection” dataset are classified according to four possible types of articles:
“article”: this type is reseved for peer-reviewed articles only
“note”: this type is used for different kinds of notes: research note, critical note, summary note, etc.
“compterendu”: this type is used for reviews
“autre” (other): this type is used when the three other types are not suitable.
The type of an article is tagged with the attribute @typeart:
XML path: article@typeart=””
Cultural vs Scholarly journals
Cultural journals : Following a digitization project with the Quebec cultural community, cultural journals and magazines were added to Érudit’s data.
The major distinctive particularity of cultural journals, when compared to scholarly journals, is that the “article” type is not restrain to peer-review articles for these journals and it is applied to a wide range of articles.
Also note that:
They all follow the “minimal” workflow
The references are not tagged
The only way to identify whether an article belongs to a scholarly or cultural journal is to look at its identifier.
Cultural journals articles identifier finishes with “ac”
Scholarly journals articles identifier finishes with everything else different from “ac”
Journal Type |
File |
ID example |
XML Path |
|---|---|---|---|
cultural |
ERUDITXSD300.xml |
12345ac |
article@idproprio=”12345ac” |
scholarly |
ERUDITXSD300.xml |
1234567ar |
article@idproprio=”1234567ar” |
Note
A scholarly article identifier usually ends with “ar”, but some articles do not follow this standard. All those articles belongs to scholarly journals.
Some particularities
The articles in the “Centre for Digital Scholarship collection”, although available in the Érudit dataset, present some particularities.
The XML files for the articles in this collection were not generated by Érudit and their quality may vary since there was no quality control afterward by the Érudit team on the files.
Also, a significant portion of the articles in that collection do not comply with the Érudit nomenclature for identifiers. However, all of these journals are Scholarly journals.
In addition, the PDFs are not currently available for a large part of the articles in this collection.
Finally, only the most recent files in this collection were produced by Érudit. For these articles, the PDF are available and the articles identifiers follow the Érudit rule.
Document’s Bibliographic References
If an article have references, they are available in XML, either in the text of the article (tagged for indexing) or tagged with an XML element.
For scholarly journals, if an article have references, each of them are tagged separately with an XML element in the back of the XML file with the element refbiblio.
However, the references are unstructured: Érudit identifies only the beginning and the end of a reference.
Finally, for cultural journals, if an article have references, they are in the text of the article.
Note
Please note that there is a small number of scholarly articles for which it was not possible to tag the references due to technical issues (although the references are available with the text of the article).
FAQ
What’s in the “Érudit - Scholarly and Cultural Journals Collection”?
What is included in the “Érudit - Scholarly and Cultural Journals Collection” are the Journals published on Érudit, including some archive journals that ceased publishing. In the journals list, these journals are the one that can be found in both the “Érudit” and “Centre for Digital Scholarship” collections (the journals of these two collections are available by default on Érudit Website).
What are the assets?
Q: What means the assets in “Érudit - Scholarly and Cultural Journals Collection”?
A: “Érudit - Scholarly and Cultural Journals Collection” provides access to the images, videos and other files within the article content. The assets represents the digital files available in each document.