Datasets Documentation
Update Date: 2024-08-01
Datasets Providers
Datasets in Graphs
The entire archive is represented by the graphs bellow.
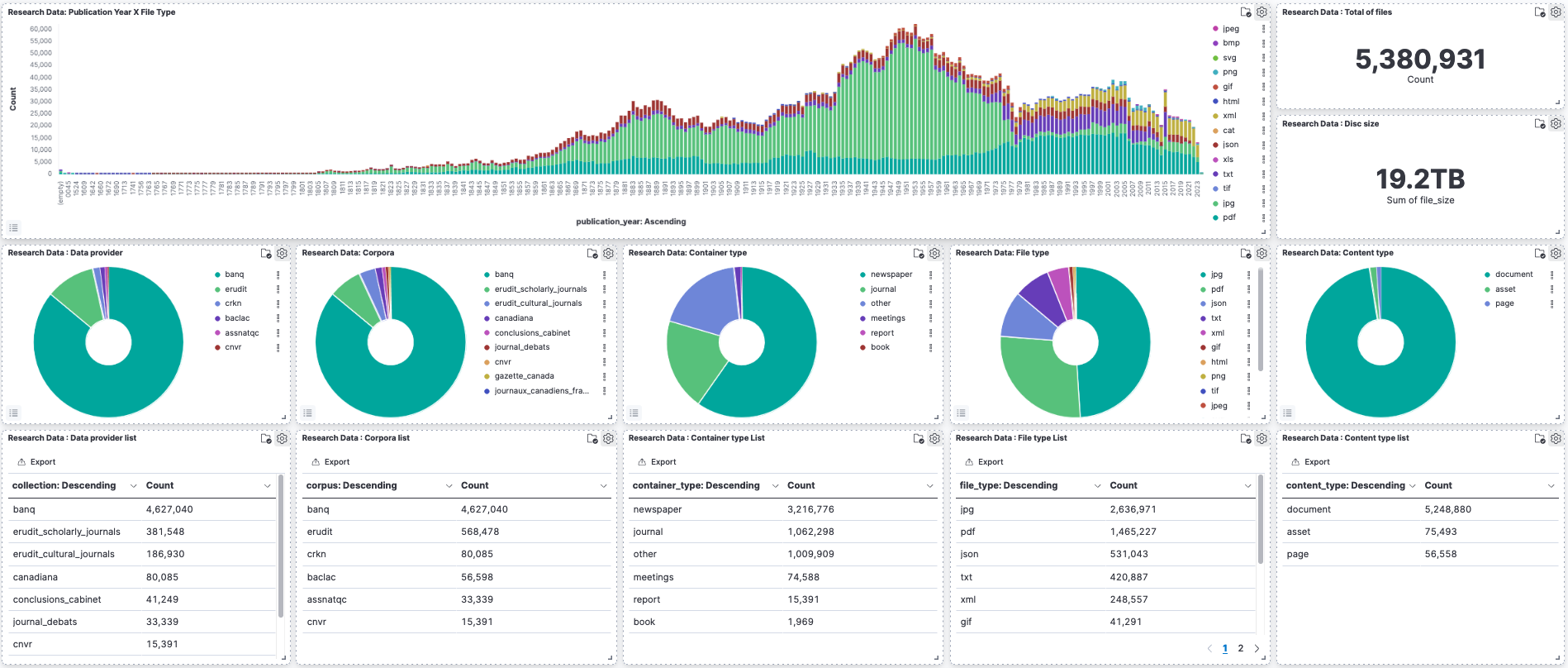
The raw data used to produce these graphs is available in corpus_report_2023_03_30.zip.
Corpus Report
The corpus report TSV file (corpus_report_2023_03_30.zip) has a list of all the documents available in the “Research Data” dataset. The fields of this TSV file are explaned bellow.
Note
Note that this TSV file contains too many rows to be opened with Microsoft Excel or with Libre Office Calc. Its data must be parsed using a programming language such as Python or other.
With this TSV file, researchers can identify which files they are intended to work with filtering those files based on some basic metadata, and estimate the local storage size required to store the required dataset.
The fields available for each dataprovider are described in the table bellow.
Field name |
Is mandatory |
BAnQ |
LAC |
CRKN |
Erudit |
|---|---|---|---|---|---|
file_identifier |
yes |
yes |
yes |
yes |
yes |
container_identifier |
no |
no |
no |
no |
yes |
container_title |
no |
yes |
no |
no |
yes |
container_type |
no |
yes |
yes |
yes |
yes |
content_type |
no |
yes |
yes |
yes |
yes |
corpus |
yes |
yes |
yes |
yes |
yes |
collection |
yes |
yes |
yes |
yes |
yes |
file_type |
yes |
yes |
yes |
yes |
yes |
file_size |
yes |
yes |
yes |
yes |
yes |
publication_year |
yes |
yes |
yes |
yes |
yes |
Fields documentation
file_identifier
The unique file identifier. It represents the file path in the file system.
container_identifier
The unique identifier of the container of a document.
This field is not available for all datasets. There are some data providers that do not provide this information.
It is an optional field.
container_title
The container title.
This field is not available for all datasets. There are some data providers that do not provide this information.
It is an optional field.
exemple:
The container title could be a journal title, a newspaper title, a book title.
container_type
The container type.
We do our best effort to better identify this information for all dataset, even if it was not provided to us.
It is an optional field.
exemple:
journal
newspaper
meetings
book
other
etc
content_type
The content type.
We do our best effort to better identify this information for all dataset, even if it is not provided to us.
It is an optional field.
exemple:
document : The fulltext is comprised in the file
asset : It represents the assets (images, tables, video, audio, etc) of a document
page : Not the fulltext, but a page of a document. Usually available in datasets of digitized images. To have access to the fulltext it is required to identify the group of images that belongs to a document. As for exemple, the content of Cabinet Conclusions, 1944 to 1979. Unfortunatelly somethimes therer are no ways to aggregate pages of a document because there are no data available for the container (container_identifer, container_title).
corpus
The identifier of a data provider.
It is a mandatory field.
exemple:
banq
baclac
canadiana
erudit
collection
The identifier of a collection provided by a data provider.
It is a mandatory field.
There are some cases, as for exemple in the Bibliothèque et Archives nationales du Québec dataset, we are not able to clearly identify the files collection. In this case the collection field is filled with the same identifier of the data provider.
canadiana_serial (canadiana)
conclusions_cabinet (baclac)
gazette_canada (baclac)
journaux_canadiens_francais (baclac)
erudit_journals (erudit)
banq (banq)
file_type
The extension of each file.
it is a mandatory field.
exemple:
pdf
xml
gif
jpg
tif
txt
png
file_size
The size of one file in bytes.
This field can be used to estimate the size of the dataset a researcher aims to download.
it is a mandatory field.
publication_year
The publication year of the content available in the file.
We do our best effort to better identify this information for all dataset, even if it was not provided to us.
it is a mandatory field.